一、引子
上一篇文章,我们讲述了:《MySQL 是如何查询的?》
那么,如果我们执行了一条更新语句,MySQL 是如何工作的呢?
例如:
select * from set = "test" where id = 647;
首先,上篇文章:我们讲述了 MySQL 的设计架构。
从MySQL的流程上来说,依然会
先经过 Server 层:
连接器:(连接/校验权限)
分析器:(词法/语法分析)
优化器:(选择索引)
执行器:(调用
engine层接口,执行更新操作)
再到 Engine 层:调用具体的更新接口。
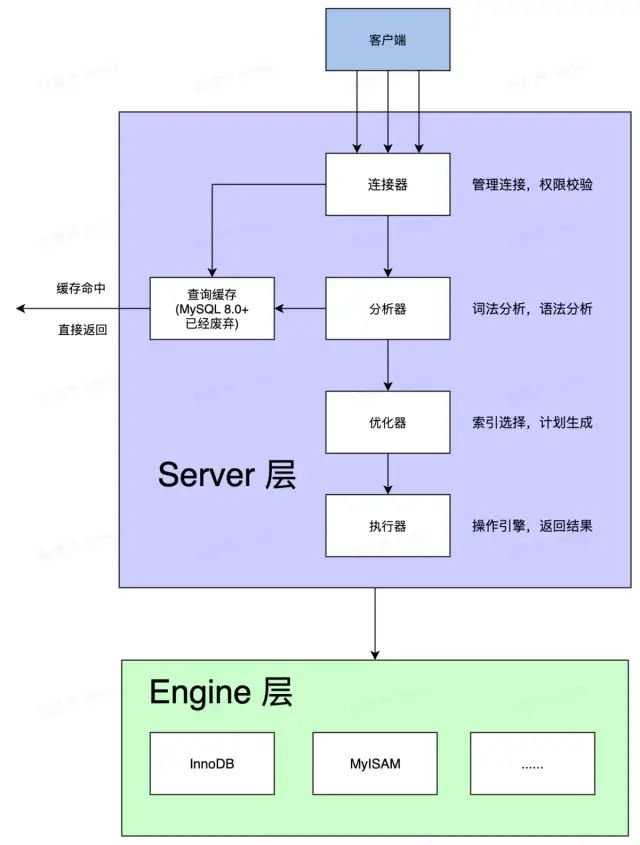
MySQL架构
我们知道,磁盘的I/O是有瓶颈的。
如果每次更新都直接写磁盘,MySQL很容易就会忙不过来。
因此,为了解决这个问题。MySQL采用了WAL技术(Write-Ahead Logging),即先写日志,再写磁盘。
忙的时候,先写日志。等闲下来,一起刷到磁盘。
因此,需要会两个特殊的日志模块,也是今天的主角:binlog 和 redo log。
其中,binlog对应Server层的日志。(Server层通用)redo log对应Engine层 innoDB 引擎的日志系统。(因为 innoDB 最常用,也是 MySQL 默认的存储引擎。别的存储引擎会不一样)
接下来,我们会重点介绍这两个日志系统。
二、binlog
binlog是MySQL的Server层通用归档日志。Engine层的所有存储引擎都可以使用binlog。
binlog是逻辑日志。顺序记录了数据库的DDL和DML语句。binlog日志是可以被无限追加写入的,当binlog文件写到一定大小后,会自动切换到下一个文件。并不会覆盖原来的binlog文件。
binlog 的作用:
1. 数据恢复
只要我们有数据库在某个时刻的备份,以及这个时刻后的所有 binlog。那么,我们就能恢复数据库的数据。
我们日常工作中, 我们的DBA同学经常可以帮我们恢复数据库的数据到任何一秒。
他们用的就是 binlog 。
2. 主从复制
为了提高 MySQL 的效率,我们经常会做读写分离,即一主多从。
一个主库(写库),多个从库(读库)。
这时,从库可以监听主库的 binlog 日志,同步写库的所有更改操作。
三、redo log
redo log是MySQLEngine层,InnoDB存储引擎特有的日志。又称为“重做日志”。
问:为什么称作“重做日志”呢?
答:因为它保证了MySQL的Crash-Safe能力。
即使MySQL发生了异常,重启后,数据也不会丢失。
redo log 是物理日志。可以理解成一个固定空间大小的队列,会被无限循环复写。
每当 MySQL 闲下来,或者 redo log 文件空间被写满了。
那么,MySQL 就会将 redo log 队头的一些数据刷入磁盘,并且清除已经刷入磁盘的redo log日志。
然后,继续更新工作,将更新的数据写入队尾。
四、两阶段提交
所谓两阶段提交,就是
MySQL为了保证一致性,在 innoDB 引擎下,会将写 binlog 与 redo log 作为一个事务一起提交。
不会出现先写binlog或者先写redo log的情况。
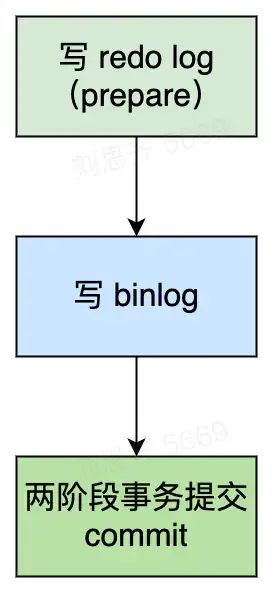
两阶段提交
版权声明:本文内容来自简书>作者 : 齐舞647,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。原文链接:https://www.jianshu.com/p/06cc23874950如有涉及到侵权,将立即予以删除处理。在此特别鸣谢:简书博主>齐舞647的创作。此篇文章所有版权归原作者所有,与本公众号无关,商业转载请联系作者获得授权,非商业转载请注明出处。。