在分布式系统中,缓存技术用于提升性能和响应速度。
Redis 作为一款高性能的键值存储系统,广泛应用于缓存、消息队列和会话管理等场景。随着业务规模的扩大,单机 Redis 的性能和可用性逐渐无法满足需求。
因此,搭建高可用的 Redis 集群可以解决这一问题。我将详细介绍 Redis 集群的两种常见方案——哨兵模式和高可用集群模式,并重点探讨 Redis 高可用集群的搭建过程、Java 客户端操作方式以及集群的原理分析。
一、Redis 集群方案对比
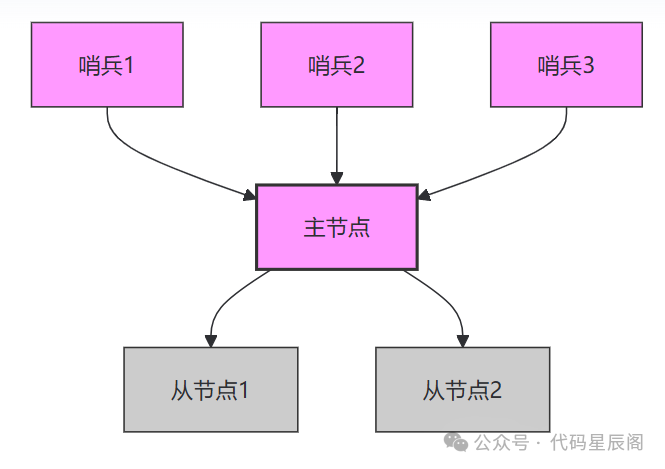
(一)哨兵模式
在 Redis 早期版本中,哨兵(Sentinel)模式是实现高可用的主要方式。哨兵通过监控主节点(master)的状态,在主节点发生故障时自动触发主从切换,将某个从节点(slave)提升为新的主节点。
然而,哨兵模式存在以下局限性:
配置复杂:哨兵的配置较为繁琐,需要手动配置哨兵节点和主从节点的关系。
性能瓶颈:在主从切换瞬间,可能会导致访问中断。
并发能力有限:哨兵模式只有一个主节点对外提供服务,无法支持高并发。
单节点内存限制:主节点内存不宜过大,否则会影响持久化文件的大小和主从同步效率。
哨兵模式架构图

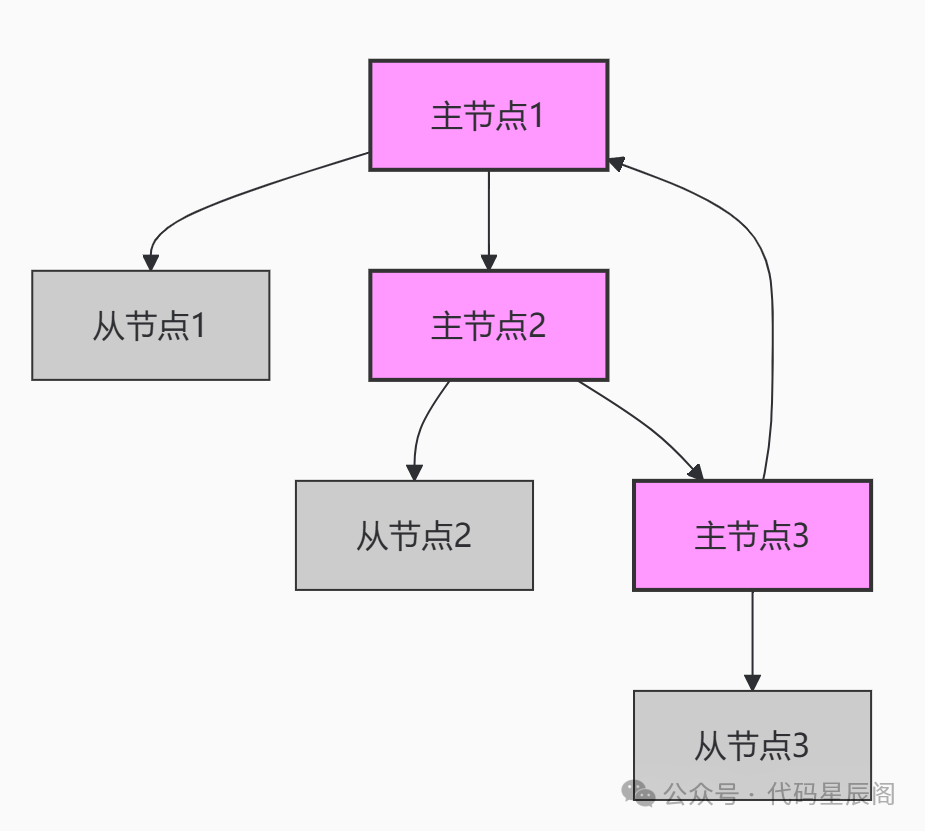
(二)高可用集群模式
Redis 集群是一种分布式架构,由多个主从节点组成,具备复制、高可用和分片特性。
与哨兵模式相比,Redis 集群具有以下显著优势:
无需哨兵:集群模式下,节点移除和故障转移无需依赖哨兵,简化了配置。
水平扩展:集群没有中心节点,支持水平扩展,官方推荐最多扩展到 1000 个节点。
高性能和高可用性:集群模式的性能和可用性优于哨兵模式。
配置简单:集群的配置过程较为简单,易于维护。
高可用集群架构图
二、Redis 高可用集群搭建
(一)集群架构设计
为了保证高可用性,Redis 集群至少需要三个主节点。本文以三台机器为例,每台机器部署一主一从,共六个 Redis 实例。每个主节点负责一部分槽位(slots),槽位的总数为 16384 个。
(二)搭建步骤
1. 创建目录结构
在第一台机器的 /usr/local 目录下创建 redis-cluster 文件夹,并在其下创建两个子文件夹 7001 和 7004,分别用于存放主节点和从节点的配置文件和数据。
mkdir -p /usr/local/redis-clustermkdir 7001 70042. 修改配置文件
将
redis.conf配置文件复制到7001目录下,并修改以下配置:daemonize yesport 7001pidfile /var/run/redis_7001.piddir /usr/local/redis-cluster/7001/cluster-enabled yescluster-config-file nodes-7001.confcluster-node-timeout 10000protected-mode noappendonly yesrequirepass mypasswordmasterauth mypassword其中,
cluster-enabled开启集群模式,cluster-config-file指定集群节点信息文件,cluster-node-timeout设置节点超时时间。3. 复制配置文件
将修改后的配置文件复制到
7004目录下,并修改端口号等配置项。对于其他两台机器,分别使用7002和7005,7003和7006作为端口号。4. 启动 Redis 实例
分别启动六个 Redis 实例,并检查是否启动成功:
/usr/local/redis-5.0.3/src/redis-server/usr/local/redis-cluster/700*/redis.confps -ef | grep redis5. 创建集群
使用
redis-cli工具创建集群:/usr/local/redis-5.0.3/src/redis-cli -a mypassword--cluster create--cluster-replicas 1192.168.1.101:7001192.168.1.102:7002192.168.1.103:7003192.168.1.101:7004 192.168.1.102:7005 192.168.1.103:7006其中,
--cluster-replicas 1表示每个主节点有一个从节点。6. 验证集群
连接任意一个节点并验证集群状态:
/usr/local/redis-5.0.3/src/redis-cli -a mypassword -c -h 192.168.1.101 -p 7001cluster infocluster nodes(三)集群搭建流程图
三、Java 客户端操作 Redis 集群
(一)依赖引入
使用 Jedis 客户端操作 Redis 集群,需在项目中添加以下依赖:
dependency>groupId>redis.clientsgroupId>artifactId>jedisartifactId>version>3.6.0version>dependency>(二)代码示例
以下是一个简单的 Java 代码示例,用于连接和操作 Redis 集群:
import redis.clients.jedis.HostAndPort;import redis.clients.jedis.JedisCluster;import java.util.HashSet;import java.util.Set;public class JedisClusterDemo {public static void main(String[] args) {Set nodes = new HashSet();nodes.add(new HostAndPort("192.168.1.101", 7001));nodes.add(new HostAndPort("192.168.1.102", 7002));nodes.add(new HostAndPort("192.168.1.103", 7003));nodes.add(new HostAndPort("192.168.1.101", 7004));nodes.add(new HostAndPort("192.168.1.102", 7005));nodes.add(new HostAndPort("192.168.1.103", 7006));try (JedisCluster jedisCluster = new JedisCluster(nodes, 6000, 5000, 10, "mypassword")) {jedisCluster.set("testKey", "testValue");System.out.println("Retrieved value: " + jedisCluster.get("testKey"));} catch (Exception e) {e.printStackTrace();}}}(三)Spring Boot 整合
在 Spring Boot 项目中,可以通过以下配置整合 Redis 集群:
spring:redis:database: 0timeout: 3000password: mypasswordcluster:nodes: 192.168.1.101:7001,192.168.1.102:7002,192.168.1.103:7003,192.168.1.101:7004,192.168.1.102:7005,192.168.1.103:7006lettuce:pool:max-idle: 50min-idle: 10max-active: 100max-wait: 1000(四)Java 操作流程图
四、Redis 集群原理分析
(一)槽位机制
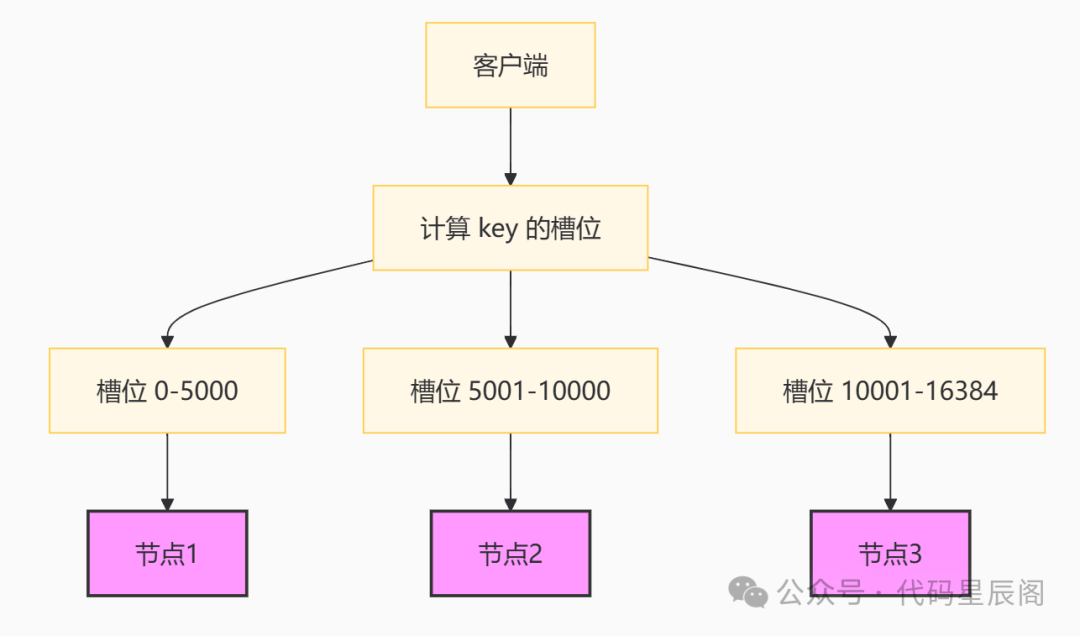
Redis Cluster 将所有数据划分为 16384 个槽位(slots),每个节点负责一部分槽位。
客户端通过 CRC16 算法对 key 进行哈希,然后对 16384 取模,确定 key 所在的槽位:
HASH_SLOT = CRC16(key) mod 16384客户端连接集群时会缓存槽位信息,若槽位信息发生变化,客户端会通过跳转指令(ASK 或 MOVED)更新本地缓存。
槽位分配示意图
(二)节点间通信机制
Redis Cluster 采用 Gossip 协议进行节点间通信,维护集群的元数据。Gossip 协议包含以下几种消息:
meet:新节点加入集群时,其他节点通过 meet 消息将其纳入集群。
ping:节点定期发送 ping 消息,包含自身状态和元数据。
pong:对 ping 和 meet 消息的响应,用于信息广播和更新。
fail:节点检测到其他节点故障时,发送 fail 消息通知其他节点。
Gossip 协议通信流程图
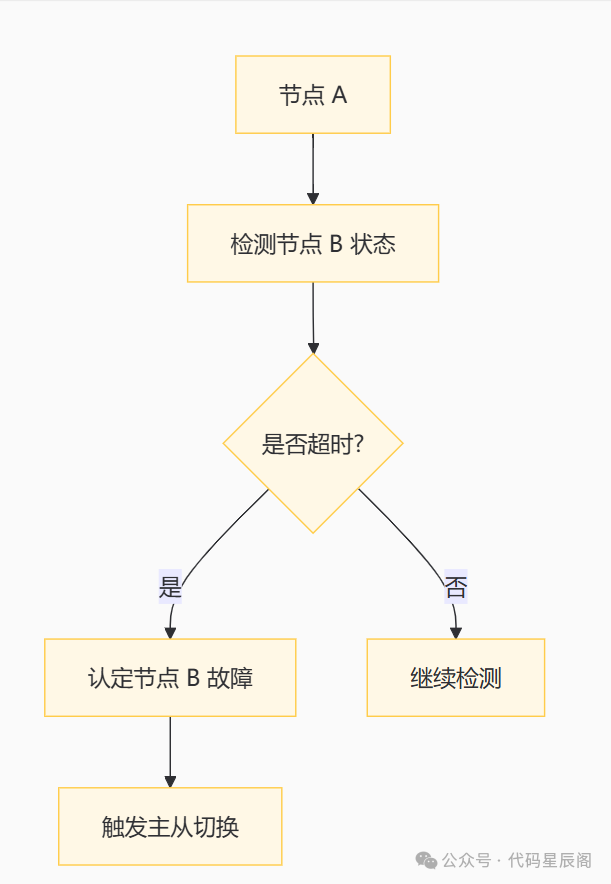
(三)网络抖动处理
为避免网络抖动导致的误判,Redis Cluster 引入了
cluster-node-timeout参数。当节点在指定时间内持续失联时,才会认定该节点故障并触发主从切换。
网络抖动处理流程图
五、总结
Redis 集群通过槽位机制和 Gossip 协议,实现了高性能、高可用的分布式存储架构。
相比哨兵模式,集群模式在扩展性和并发能力上具有显著优势。