一、基本概念
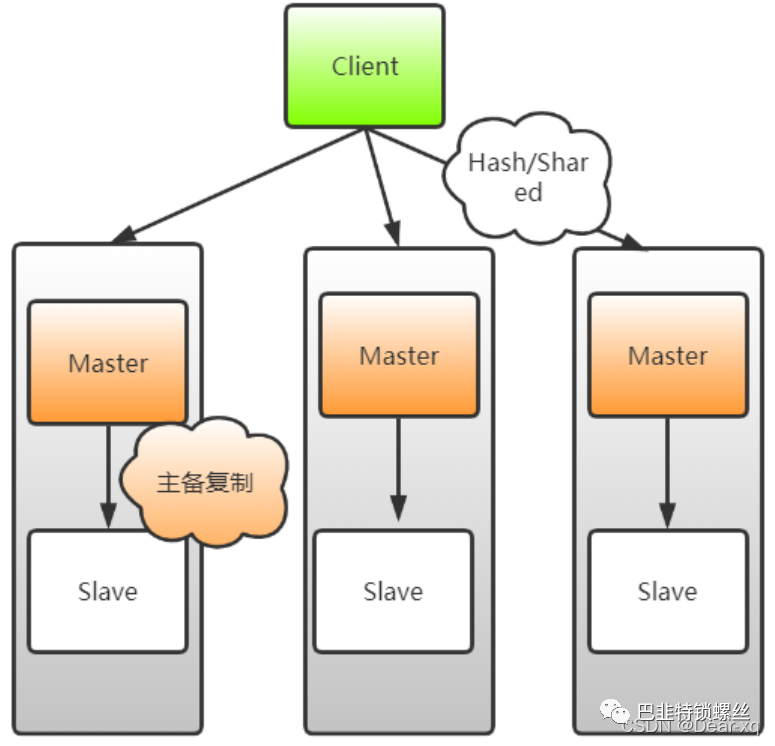
Redis数据库的Cluster集群模式是一种将数据分布到多个Redis节点的解决方案,以提高数据存储和读取的可用性和扩展性。Redis Cluster是一种分布式、高可用性的Redis数据库部署模式。它将数据划分为多个槽(slot),每个节点负责处理一部分槽的数据。通过对槽的划分和分配,实现数据在多个节点之间的分布式存储和访问。Redis Cluster使用Gossip协议来进行节点间的信息传递和集群管理。
Cluster集群模式的核心思想是将数据分片(Sharding)存储在多个Redis节点上,每个节点负责存储一部分数据。客户端与Cluster集群交互时,通过计算CRC16校验码将数据定位到具体的节点上。Cluster集群使用Gossip协议进行节点间的通信,以实现自动分片、故障转移和数据一致性。
Cluster集群模式特点:
1. 数据分片:Cluster集群模式将数据分片存储在多个Redis节点上,每个节点只负责存储部分数据,提高了数据的可用性和扩展性。
2. 高可用性:Cluster集群模式支持主从复制,当某个节点故障时,可以自动将一个从节点提升为新的主节点,保证了数据的可用性。
3. 自动分片:Cluster集群模式支持自动分片,客户端发送数据时,会自动计算CRC16校验码,根据校验码将数据定位到具体的节点上。
4. 故障转移:Cluster集群模式支持故障转移,当某个节点故障时,可以自动将故障节点上的数据迁移到其他节点上,保证了数据的可靠性。
5. 数据一致性:Cluster集群模式使用Gossip协议进行节点间的通信,保证了数据的一致性。
Cluster集群模式应用场景
1. 大规模数据存储:对于需要存储大规模数据的场景,使用Cluster集群模式可以将数据分布到多个Redis节点上,提高数据的可用性和扩展性。
2. 高并发读写:对于高并发读写的场景,使用Cluster集群模式可以将请求分散到多个节点上,提高系统的吞吐量。
3. 分布式系统:对于分布式系统,使用Cluster集群模式可以保证数据的一致性和可靠性,提高系统的可用性。
与Sentinel集群的区别
1. 数据分片方式:Cluster集群模式是将数据分片存储在多个Redis节点上,而Sentinel集群则是在一个Redis实例中存储所有数据,通过主从复制实现高可用性。
2. 数据一致性:Cluster集群模式使用Gossip协议进行节点间的通信,保证了数据的一致性。而Sentinel集群则依赖于Redis的主从复制机制,主节点故障时,从节点可以接管。
3. 扩展性:Cluster集群模式支持水平扩展,可以通过添加更多的节点来提高系统的存储和读取能力。而Sentinel集群则不支持水平扩展,只能通过添加更多的Redis实例来提高系统的存储和读取能力。
4. 配置和管理:Cluster集群模式的配置相对复杂,需要配置多个Redis节点和转发客户端的请求。而Sentinel集群的配置相对简单,只需要配置一个Redis实例和一个或多个Sentinel实例。
小结:(1)Redis Cluster 适用于大规模分布式场景,横向扩展和数据分片是其关键特点。(2)Sentinel 适用于对于高可用性要求较高的单节点或主从结构,它通过监控和故障转移来保证系统的稳定性。(3)Redis Cluster 更适合处理读写高并发的业务,而 Sentinel 更注重保证系统的高可用性。
二、实例配置
1、基本环境
Redis Cluster 采用无中心结构,每个节点都可以保存数据和整个集群状态,每个节点都和其他所有节点 连接。Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为 主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后, 顶替主节点。
配置一个 Redis Cluster 我们需要准备至少 6 台 Redis。
总结:读请求分配给 Slave 节点,写请求分配给 Master,数据同步从 Master 到 Slave 节点。
第一台服务器:192.168.1.137 6个redis实例(6371-6376)
第二台服务器:192.168.1.138 6个redis实例(6371-6376)
2、创建目录
mkdir -p /usr/local/redis/cluster/conf /usr/local/redis/cluster/data /usr/local/redis/cluster/log
3、修改配置文件
# vim redis-6371.conf
# 放行访问IP限制bind 0.0.0.0# 端口port 6371# 后台启动daemonize yes# 日志存储目录及日志文件名logfile "/usr/local/redis/cluster/log/redis-6371.log"# rdb数据文件名dbfilename dump-6371.rdb# aof模式开启和aof数据文件名appendonly yesappendfilename "appendonly-6371.aof"# rdb数据文件和aof数据文件的存储目录dir /usr/local/redis/cluster/data# 设置密码requirepass 123456# 从节点访问主节点密码(必须与 requirepass 一致)masterauth 123456# 是否开启集群模式,默认 no# 集群节点信息文件,会保存在 dir 配置对应目录下# 集群节点连接超时时间# 集群节点 IP# 集群节点映射端口# 集群节点总线端口
有多少个实例,就复制多少个配置文件,Vim批量修改即可。
:%s/6371/6372/g
批量替换conf配置文件的内容,命令如下:
find /usr/local/redis/cluster/conf -type f -name '*.conf' -exec sed -i 's/192.168.1.138/192.168.1.137/g' {} +
解释:
bind 0.0.0.0:port 6371:Redis 服务器监听的端口号。daemonize yes:logfile "/usr/local/redis/cluster/log/redis-6371.log":dbfilename dump-6371.rdb:appendonly yes:appendfilename "appendonly-6371.aof":dir /usr/local/redis/cluster/data:requirepass 123456:masterauth 123456:设置集群节点的连接超时时间(单位:毫秒)。指定节点在集群中公布的端口号。指定节点在集群中公布的总线端口。
4、启动redis实例
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6371.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6372.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6373.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6374.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6375.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6376.conf
三、集群配置
1、集群创建
以俩台服务器上分别进行创建为例:
192.168.1.137:6371 192.168.1.137:6372192.168.1.137:6373 192.168.1.137:6374192.168.1.137:6375 192.168.1.137:6376--cluster-replicas 1
192.168.1.138:6371 192.168.1.138:6372192.168.1.138:6373 192.168.1.138:6374192.168.1.138:6375 192.168.1.138:6376--cluster-replicas 1
说明:--cluster-replicas 1 是 Redis 集群创建时的一个参数,它指定了集群中每个主节点对应的从节点的数量。在这里,--cluster-replicas 1 表示每个主节点有一个从节点。
创建结果输出:
> 192.168.1.138:6371 192.168.1.138:6372> 192.168.1.138:6373 192.168.1.138:6374> 192.168.1.138:6375 192.168.1.138:6376> --cluster-replicas 1Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.Adding replica 192.168.1.138:6375 to 192.168.1.138:6371Adding replica 192.168.1.138:6376 to 192.168.1.138:6372Adding replica 192.168.1.138:6374 to 192.168.1.138:6373M: 90fb02aa2878c7e95a1a1ac764a09a6c8f83233d 192.168.1.138:6371slots:[0-5460] (5461 slots) masterM: 5e38fc35334e03d7dc3ebe7e36830f6acadc582b 192.168.1.138:6372slots:[5461-10922] (5462 slots) masterM: 44c42f752005fb8348f2f8e065f670bafcbd162f 192.168.1.138:6373slots:[10923-16383] (5461 slots) masterS: 83b5358753200e153465c775a4a76a64831873ba 192.168.1.138:6374replicates 5e38fc35334e03d7dc3ebe7e36830f6acadc582bS: 88e80b2085700b1bdaee1b8c5b801dc04299cc54 192.168.1.138:6375replicates 44c42f752005fb8348f2f8e065f670bafcbd162fS: 2237cbf0b63426516016c91fa9ce077176d85cac 192.168.1.138:6376replicates 90fb02aa2878c7e95a1a1ac764a09a6c8f83233dCan I set the above configuration? (type 'yes' to accept): yesWaiting for the cluster to join.M: 90fb02aa2878c7e95a1a1ac764a09a6c8f83233d 192.168.1.138:6371slots:[0-5460] (5461 slots) master1 additional replica(s)S: 2237cbf0b63426516016c91fa9ce077176d85cac 192.168.1.138:6376slots: (0 slots) slavereplicates 90fb02aa2878c7e95a1a1ac764a09a6c8f83233dS: 88e80b2085700b1bdaee1b8c5b801dc04299cc54 192.168.1.138:6375slots: (0 slots) slavereplicates 44c42f752005fb8348f2f8e065f670bafcbd162fM: 5e38fc35334e03d7dc3ebe7e36830f6acadc582b 192.168.1.138:6372slots:[5461-10922] (5462 slots) master1 additional replica(s)S: 83b5358753200e153465c775a4a76a64831873ba 192.168.1.138:6374slots: (0 slots) slavereplicates 5e38fc35334e03d7dc3ebe7e36830f6acadc582bM: 44c42f752005fb8348f2f8e065f670bafcbd162f 192.168.1.138:6373slots:[10923-16383] (5461 slots) master1 additional replica(s)

该集群中包含 6 个 Redis 节点,3 主 3 从。
2、集群检查
/usr/local/redis/bin/redis-cli -a 123456 --cluster check 192.168.1.137:6371
[root@DB-Master data]# /usr/local/redis/bin/redis-cli -a 123456 --cluster check 192.168.1.137:6371Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.# 主节点信息192.168.1.137:6371 (694ce7e6...) -> 0 keys | 5461 slots | 1 slaves.192.168.1.137:6372 (bc13ea49...) -> 0 keys | 5462 slots | 1 slaves.192.168.1.137:6373 (7a87ed79...) -> 0 keys | 5461 slots | 1 slaves.# 主节点有多少 Key[OK] 0 keys in 3 masters.# 每个槽的平均分配情况0.00 keys per slot on average.# 集群状态检查操作由 192.168.1.137:6371执行>>> Performing Cluster Check (using node 192.168.1.137:6371)# 主节点信息以及附加的从节点个数M: 694ce7e6fd614fe4da0590e56f82ac9307229835 192.168.1.137:6371slots:[0-5460] (5461 slots) master1 additional replica(s)# 从节点信息以及复制的主节点 IDS: 8de2b7f096636e2fa7ef66aae72e0c50ebbff0bb 192.168.1.137:6375slots: (0 slots) slavereplicates 7a87ed79be4ec0023ea9a93774e4eb136dfe99c7S: bdda13fdf3c1f39b4d9c1e6148a15028f45e8fa4 192.168.1.137:6374slots: (0 slots) slavereplicates bc13ea49343fcdf80cbee55b263d5d925d46bdc7M: bc13ea49343fcdf80cbee55b263d5d925d46bdc7 192.168.1.137:6372slots:[5461-10922] (5462 slots) master1 additional replica(s)S: d05f960dd0f0e2688d2f2191aef1b94c2f66ba9c 192.168.1.137:6376slots: (0 slots) slavereplicates 694ce7e6fd614fe4da0590e56f82ac9307229835M: 7a87ed79be4ec0023ea9a93774e4eb136dfe99c7 192.168.1.137:6373slots:[10923-16383] (5461 slots) master1 additional replica(s)# 所有节点都同意槽的配置情况[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...# 所有 16384 个槽都包括在内[OK] All 16384 slots covered.
主节点日志:
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6371.log
[root@DB-Master conf]# tail -f -n 1000 /usr/local/redis/cluster/log/redis-6371.log1579:C 26 Dec 2023 14:08:50.906 # WARNING: Changing databases number from 16 to 1 since we are in cluster mode1579:C 26 Dec 2023 14:08:50.906 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.1580:C 26 Dec 2023 14:08:50.907 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo1580:C 26 Dec 2023 14:08:50.908 * Redis version=7.2.3, bits=64, commit=00000000, modified=0, pid=1580, just started1580:C 26 Dec 2023 14:08:50.908 * Configuration loaded1580:M 26 Dec 2023 14:08:50.909 * Increased maximum number of open files to 10032 (it was originally set to 1024).1580:M 26 Dec 2023 14:08:50.909 * monotonic clock: POSIX clock_gettime1580:M 26 Dec 2023 14:08:50.910 * Running mode=cluster, port=6371.1580:M 26 Dec 2023 14:08:50.910 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.# 未找到集群环境配置,当前节点 ID 为 a1cd39d24bd2c9456026d592f0fac8728cea0e291580:M 26 Dec 2023 14:08:50.910 * No cluster configuration found, I'm bf371d60c7f082e3ab0e5d2fc4503e68bdfebd1a# 服务器初始化1580:M 26 Dec 2023 14:08:50.911 * Server initialized1580:M 26 Dec 2023 14:08:50.911 * Creating AOF base file appendonly-6371.aof.1.base.rdb on server start1580:M 26 Dec 2023 14:08:50.912 * Creating AOF incr file appendonly-6371.aof.1.incr.aof on server start# 准备就绪,接受客户端连接1580:M 26 Dec 2023 14:08:50.912 * Ready to accept connections tcp1580:M 26 Dec 2023 14:16:22.200 # Missing implement of connection type tls# 配置中写入纪元时间1580:M 26 Dec 2023 14:19:11.719 * configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH1580:signal-handler (1703574432) Received SIGTERM scheduling shutdown...1580:M 26 Dec 2023 15:07:12.946 * User requested shutdown...1580:M 26 Dec 2023 15:07:12.946 * Calling fsync() on the AOF file.1580:M 26 Dec 2023 15:07:12.946 * Saving the final RDB snapshot before exiting.1580:M 26 Dec 2023 15:07:12.947 * DB saved on disk1580:M 26 Dec 2023 15:07:12.947 * Removing the pid file.1580:M 26 Dec 2023 15:07:12.947 # Redis is now ready to exit, bye bye...2468:C 26 Dec 2023 15:07:20.044 # WARNING: Changing databases number from 16 to 1 since we are in cluster mode2468:C 26 Dec 2023 15:07:20.044 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.2469:C 26 Dec 2023 15:07:20.047 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo2469:C 26 Dec 2023 15:07:20.047 * Redis version=7.2.3, bits=64, commit=00000000, modified=0, pid=2469, just started2469:C 26 Dec 2023 15:07:20.047 * Configuration loaded2469:M 26 Dec 2023 15:07:20.047 * Increased maximum number of open files to 10032 (it was originally set to 1024).2469:M 26 Dec 2023 15:07:20.047 * monotonic clock: POSIX clock_gettime2469:M 26 Dec 2023 15:07:20.048 * Running mode=cluster, port=6371.2469:M 26 Dec 2023 15:07:20.048 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.2469:M 26 Dec 2023 15:07:20.048 * No cluster configuration found, I'm 694ce7e6fd614fe4da0590e56f82ac93072298352469:M 26 Dec 2023 15:07:20.049 * Server initialized2469:M 26 Dec 2023 15:07:20.050 * Creating AOF base file appendonly-6371.aof.1.base.rdb on server start2469:M 26 Dec 2023 15:07:20.050 * Creating AOF incr file appendonly-6371.aof.1.incr.aof on server start2469:M 26 Dec 2023 15:07:20.050 * Ready to accept connections tcp2469:M 26 Dec 2023 15:08:02.961 # Missing implement of connection type tls2469:M 26 Dec 2023 15:08:25.420 * configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH2469:M 26 Dec 2023 15:08:27.434 * Replica 192.168.1.137:6376 asks for synchronization2469:M 26 Dec 2023 15:08:27.434 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'a8e4504647a7366882ddc955b16a41f66e1ce485', my replication IDs are 'beb5d56347edf97ff2c5f7c9358475f477294519' and '0000000000000000000000000000000000000000')2469:M 26 Dec 2023 15:08:27.434 * Replication backlog created, my new replication IDs are '7891afda60bc5e0d473040a124da3119b678fad6' and '0000000000000000000000000000000000000000'2469:M 26 Dec 2023 15:08:27.434 * Delay next BGSAVE for diskless SYNC2469:M 26 Dec 2023 15:08:30.356 * Cluster state changed: ok# 通过 BGSAVE 指令将数据写入磁盘(RBD操作)2469:M 26 Dec 2023 15:08:32.604 * Starting BGSAVE for SYNC with target: replicas sockets# 开启一个子守护进程执行写入2469:M 26 Dec 2023 15:08:32.604 * Background RDB transfer started by pid 2517# 数据已写入磁盘2517:C 26 Dec 2023 15:08:32.606 * Fork CoW for RDB: current 4 MB, peak 4 MB, average 4 MB2469:M 26 Dec 2023 15:08:32.607 * Diskless rdb transfer, done reading from pipe, 1 replicas still up.# 保存结束2469:M 26 Dec 2023 15:08:32.612 * Background RDB transfer terminated with success2469:M 26 Dec 2023 15:08:32.612 * Streamed RDB transfer with replica 192.168.1.137:6376 succeeded (socket). Waiting for REPLCONF ACK from replica to enable streaming# 从节点同步数据结束2469:M 26 Dec 2023 15:08:32.612 * Synchronization with replica 192.168.1.137:6376 succeeded
从节点日志:
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6374.log
3、集群节点信息查看
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.1.137 -p 6376
> cluster info #查看集群
> cluster nodes #查看节点
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.cluster_state:okcluster_slots_assigned:16384cluster_slots_ok:16384cluster_slots_pfail:0cluster_slots_fail:0cluster_known_nodes:6cluster_size:3cluster_current_epoch:6cluster_my_epoch:1cluster_stats_messages_ping_sent:4282cluster_stats_messages_pong_sent:4300cluster_stats_messages_meet_sent:1cluster_stats_messages_sent:8583cluster_stats_messages_ping_received:4300cluster_stats_messages_pong_received:4283cluster_stats_messages_received:8583total_cluster_links_buffer_limit_exceeded:0d05f960dd0f0e2688d2f2191aef1b94c2f66ba9c 192.168.1.137:6376@16376 myself,slave 694ce7e6fd614fe4da0590e56f82ac9307229835 0 1703578897000 1 connected694ce7e6fd614fe4da0590e56f82ac9307229835 192.168.1.137:6371@16371 master - 0 1703578895000 1 connected 0-5460bc13ea49343fcdf80cbee55b263d5d925d46bdc7 192.168.1.137:6372@16372 master - 0 1703578896245 2 connected 5461-109228de2b7f096636e2fa7ef66aae72e0c50ebbff0bb 192.168.1.137:6375@16375 slave 7a87ed79be4ec0023ea9a93774e4eb136dfe99c7 0 1703578897263 3 connectedbdda13fdf3c1f39b4d9c1e6148a15028f45e8fa4 192.168.1.137:6374@16374 slave bc13ea49343fcdf80cbee55b263d5d925d46bdc7 0 1703578895219 2 connected7a87ed79be4ec0023ea9a93774e4eb136dfe99c7 192.168.1.137:6373@16373 master - 0 1703578896000 3 connected 10923-16383###################################################节点1(当前连接节点):节点ID:d05f960dd0f0e2688d2f2191aef1b94c2f66ba9c角色:myself(当前连接的节点),slave(从节点)主节点ID:694ce7e6fd614fe4da0590e56f82ac9307229835从节点复制偏移量:0连接状态:connected节点2:节点ID:694ce7e6fd614fe4da0590e56f82ac9307229835角色:master(主节点)从节点列表:无复制偏移量:0连接状态:connected槽分配:0-5460
四、集群环境验证与测试
使用6376节点进行连接:
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.1.137 -p 6376
192.168.1.137:6376> set name test-> Redirected to slot [5798] located at 192.168.1.137:6372OK192.168.1.137:6372> set age 18-> Redirected to slot [741] located at 192.168.1.137:6371OK192.168.1.137:6371> set address xianOK192.168.1.137:6371> get age"18"192.168.1.137:6371> get name-> Redirected to slot [5798] located at 192.168.1.137:6372"test"
说明:在Redis集群中,槽(slot)是对数据进行分片的单位。每个槽都被分配给集群中的一个节点。当你执行一些操作时,如果该操作涉及的槽与当前连接的节点不匹配,Redis会返回一个"Redirected"信息,并将请求重定向到正确的节点上。
192.168.1.137:6376> set name test:在槽 [5798] 上设置了键 "name" 的值为 "test"。然后,由于槽 [5798] 的负责节点不是当前连接的节点(6376),所以发生了重定向。
-> Redirected to slot [5798] located at 192.168.1.137:6372:这是一个重定向的信息,指示客户端应该连接到槽 [5798] 所在的节点(6372)来执行后续的操作。
192.168.1.137:6372> set age 18:在槽 [741] 上设置了键 "age" 的值为 "18"。同样,由于槽 [741] 的负责节点不是当前连接的节点(6372),所以发生了重定向。
-> Redirected to slot [741] located at 192.168.1.137:6371:再次发生了重定向,指示客户端应该连接到槽 [741] 所在的节点(6371)。
192.168.1.137:6371> set address xian:在槽 [5798] 上设置了键 "address" 的值为 "xian"。
192.168.1.137:6371> get age:获取键 "age" 的值。由于槽 [741] 不匹配当前连接的节点,再次发生了重定向。
-> Redirected to slot [5798] located at 192.168.1.137:6372:重定向到槽 [5798] 所在的节点。
192.168.1.137:6372> get name:获取键 "name" 的值,最终成功返回 "test"。
这是Redis集群在处理分布式数据时的一种行为。当数据分布在多个节点上时,客户端可能需要通过重定向从一个节点获取或写入数据。这确保了集群的负载均衡和高可用性。
五、集群环境的关闭和释放
1、问题背景:
经常出现集群创建出现错误,信息如下:
[root@DB-Master conf]# /usr/local/redis/bin/redis-cli -a 123456 --cluster create> 192.168.1.137:6371 192.168.1.137:6372> 192.168.1.137:6373 192.168.1.137:6374> 192.168.1.137:6375 192.168.1.137:6376> --cluster-replicas 1Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.[ERR] Node 192.168.1.137:6371 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
2、问题分析:
这个错误提示表明节点 192.168.1.137:6371 不是空的,可能已经包含其他节点的信息(通过 CLUSTER NODES 命令查看)或者包含了数据库0中的某些键。在创建Redis集群时,所有的节点都必须是空的,没有包含其他节点的信息。
3、问题处理
1)清空节点数据
/usr/local/redis/bin/redis-cli -a 123456 -h 192.168.1.137 -p 6371
> CLUSTER NODES
> FLUSHALL # 清空节点数据:
2)清空集群data文件夹
3)停止redis实例
pkill redis
4)重启redis实例
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6371.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6372.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6373.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6374.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6375.conf/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6376.conf
5)重新创建redis cluster集群
192.168.1.137:6371 192.168.1.137:6372192.168.1.137:6373 192.168.1.137:6374192.168.1.137:6375 192.168.1.137:6376--cluster-replicas 1#如果cluster-replicas是2,则需要至少9个实例