首先我来几个简单的查询指令
添加
向索引 products 添加一条新数据
POST products/_doc{"name": "Smartphone","price": 699,"category": "Electronics","in_stock": true}
指定 ID 添加数据
PUT products/_doc/1{"name": "Laptop","price": 999,"category": "Electronics","in_stock": true}
查询
查询索引 products 中的所有数据
GET products/_search{"query": {"match_all": {}}}
根据条件查询数据
GET products/_search{"query": {"match": {"name": "laptop"}}}
分页查询
GET products/_search{"from": 0,"size": 10,"query": {"match_all": {}}}
删除
删除指定ID数据
DELETE products/_doc/1更新
更新指定ID
POST products/_update/1{"doc": {"price": 899}}
添加索引(入门)
PUT products{"mappings": {"properties": {"name": { "type": "text" },"price": { "type": "float" },"category": { "type": "keyword" },"in_stock": { "type": "boolean" }}}}
添加分词索引
添加分词插件
分词插件有很多,这里我就使用ik分词器
首先进入容器
执行如下指令,版本最好要对应上
bin/elasticsearch-plugin install https://github.com/infinilabs/analysis-ik/releases/download/v8.2.3/elasticsearch-analysis-ik-8.2.3.zip添加索引
ik_max_word是插件分词器
comma_tokenizer是我们自定义的分词
DELETE /productsPUT /products{"settings": {"analysis": {"analyzer": {"ik_max_word": {"type": "ik_max_word"},"comma_analyzer": {"type": "custom","tokenizer": "comma_tokenizer"}},"tokenizer": {"comma_tokenizer": {"type": "char_group","tokenize_on_chars": [","]}}}},"mappings": {"properties": {"category": {"type": "text","analyzer": "ik_max_word"},"name": {"type": "text","analyzer": "comma_analyzer"}}}}
提示成功后我们接着添加一些种子数据
POST products/_bulk{ "index": { "_id": 1 } }{ "name": "苹果", "price": 699, "category": "苹果手机 绿色 8+128", "in_stock": true }{ "index": { "_id": 2 } }{ "name": "苹果", "price": 999, "category": "苹果手机 绿色 8+256", "in_stock": true }{ "index": { "_id": 3 } }{ "name": "苹果", "price": 199, "category": "苹果手机 红色 8+128", "in_stock": false }{ "index": { "_id": 4 } }{ "name": "苹果", "price": 199, "category": "苹果手机 红色 8+256", "in_stock": false }
商品搜索
我们可以先获取分词看看我们输入"苹果红色"会出现什么效果
GET products/_analyze{"analyzer": "ik_max_word","text": "苹果红色"}
可以看出我们的分词器应用,在右边我们看出"苹果"和"红色"作为了两个分词token
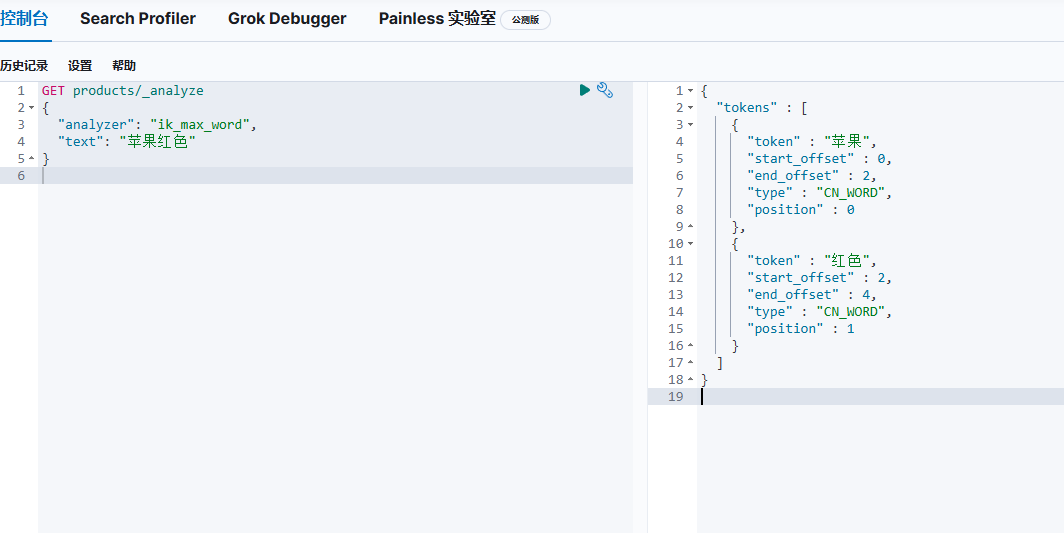
那么当我们把分词结果token放入真实的查询条件中
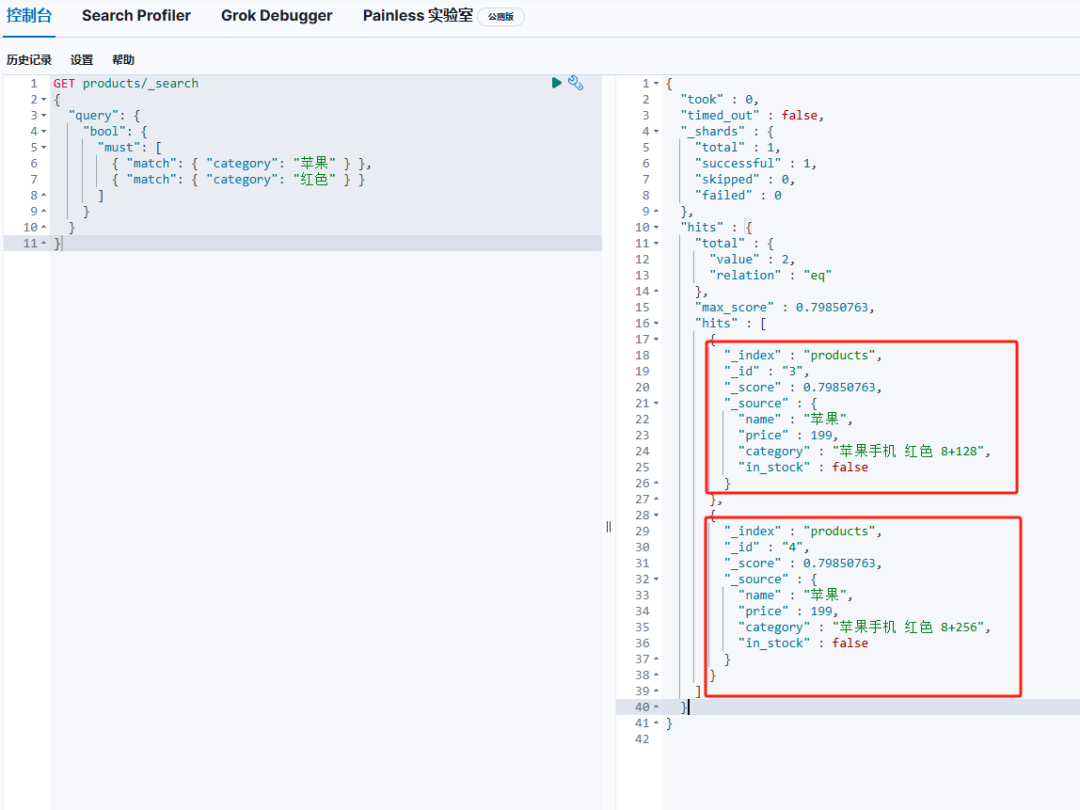
GET products/_search{"query": {"bool": {"must": [{ "match": { "category": "苹果" } },{ "match": { "category": "红色" } }]}}}
我们可以看到执行结果,只要是苹果红色产品就搜索出来了
至此,我们的商品基础查询已经完成。
es的强大功能我们只是探索了其一,接下来我们将进行一些代码的实战。
实战代码(java)
添加依赖
dependency>groupId>co.elastic.clientsgroupId>artifactId>elasticsearch-javaartifactId>version>8.12.2version>dependency>dependency>groupId>jakarta.jsongroupId>artifactId>jakarta.json-apiartifactId>version>2.0.1version>dependency>dependency>groupId>org.elasticsearch.clientgroupId>artifactId>elasticsearch-rest-clientartifactId>version>8.12.2version>dependency>
配置文件
/*** es搜索服务配置*/public class ElasticsearchClientConfig {private String serverUrl;private String apiKey;public ElasticsearchClient elasticsearchClient() {RestClient restClient = RestClient.builder(HttpHost.create(serverUrl)).setDefaultHeaders(new Header[]{new BasicHeader("Authorization", "ApiKey " + apiKey)}).build();RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());return new ElasticsearchClient(transport);}}
获取分词
private ElasticsearchClient client;public ListAnalyzeToken> analyzeText(String indexName, String text) {try {if (StringUtils.isBlank(text)) return new ArrayList();// 创建AnalyzeRequest,使用ik_max_word分析器AnalyzeRequest request = AnalyzeRequest.of(a -> a.text(text) // 传入需要分词的文本.index(indexName).analyzer("ik_max_word") // 使用ik_max_word分析器);// 执行分词分析AnalyzeResponse response = client.indices().analyze(request);// 获取分析结果ListAnalyzeToken> tokens = response.tokens();return tokens;} catch (Exception ex) {log.error("分词异常", ex);throw new ServiceException("分词异常:" + ex.getMessage());}}
添加数据
public void insertData(String indexName, ListMapString, Object>> dataList,String fieldId) {try {ListBulkOperation> bulkOperations = new ArrayList();for (MapString, Object> data : dataList) {// 创建 BulkOperation 并添加到列表中BulkOperation operation = new BulkOperation.Builder().index(idx -> idx.index(indexName) // 替换为您的索引名称.id(data.get(fieldId).toString()) // 文档ID,指定那个字段名称作为主键.document(data)) // 文档数据.build();bulkOperations.add(operation);}// 发送批量请求BulkResponse response = client.bulk(b -> b.operations(bulkOperations));// 响应状态if (response.errors()) {response.items().forEach(item -> {if (item.error() != null) {throw new ServiceException("添加集合失败:" + item.error().reason());}});} else {//添加成功}} catch (Exception ex) {log.error("添加集合失败:" + indexName, ex);throw new ServiceException("添加集合失败:" + ex.getMessage());}}
查询数据
public SearchItemResultDto searchShop(ShopQuery query) {int from = (query.getPage() - 1) * query.getSize();List analyzeTokens = analyzeText(query.getIndexName(), query.getSearchKey());SearchItemResultDto data = new SearchItemResultDto();List mustConditions = new ArrayList();//关键词for (AnalyzeToken analyzeToken : analyzeTokens) {Query filter = Query.of(q -> q.match(m -> m.field("searchName").query(analyzeToken.token())));mustConditions.add(filter);}//地区if (!StringUtils.isBlank(query.getArea())) {Query filter = Query.of(q -> q.match(m -> m.field("area").query(query.getArea())));mustConditions.add(filter);}//品牌if (!StringUtils.isBlank(query.getBrand())) {Query filter = Query.of(q -> q.match(m -> m.field("brand").query(query.getBrand())));mustConditions.add(filter);}// //品牌首字母// if (!StringUtils.isBlank(query.getBrandPrefix())) {// Query filter = Query.of(q -> q.match(m -> m.field("brandPrefix").query(query.getBrandPrefix())));// mustConditions.add(filter);// }// //品目// if (!StringUtils.isBlank(query.getCategory())) {// Query filter = Query.of(q -> q.match(m -> m.field("category").query(query.getCategory())));// mustConditions.add(filter);// }BoolQuery boolQuery = BoolQuery.of(b -> b.must(mustConditions));List results = new ArrayList();// 创建搜索请求SearchRequest searchRequest = new SearchRequest.Builder().index(ShopItemDto.KEY).query(Query.of(q -> q.bool(boolQuery))).from(from).size(query.getSize()).build();try {// 执行搜索请求SearchResponse response = client.search(searchRequest, ShopItemDto.class);// 处理搜索结果for (Hit hit : response.hits().hits()) {results.add(hit.source());}data.setData(results);data.setTotal(response.hits().total().value());return data;} catch (Exception ex) {log.error("搜索异常", ex);throw new ServiceException("搜索异常:" + ex.getMessage());}}
搜索参数
/*** @Author:HDW* @Description: 商品搜索参数**/@Datapublic class ShopQuery {/*** 索引名称*/private String indexName;/*** 搜索关键词*/private String key;/*** 实际搜索*/private String searchKey;/*** 当前页*/private int page;/*** 分页大小*/private int size;/*** 品牌*/private String brand;/*** 品牌首字母*/private String brandPrefix;/*** 品目id列表*/private String category;/*** 地区*/private String area;}
结果集
/*** @Author:HDW* @Description: 接收商品搜索dto**/public class SearchItemResultDto {private long total;private List data = new ArrayList();}
/*** @Author:HDW* @Description: 商品搜索dto**/public class ShopItemDto {public static final String KEY = "product";public String spu;public String sku;public String spuName;public String skuName;public String spec;public double price;public String picture;public int count;public String searchName;public String brand;public String brandPrefix;public String category;public String supplier;public String area;}
删除索引数据
/*** @Author:HDW* @Description: 商品搜索dto**/public class ShopItemDto {public static final String KEY = "product";public String spu;public String sku;public String spuName;public String skuName;public String spec;public double price;public String picture;public int count;public String searchName;public String brand;public String brandPrefix;public String category;public String supplier;public String area;}